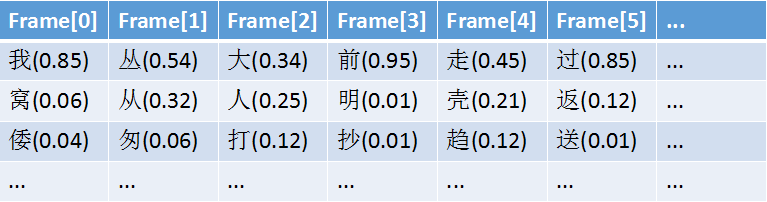
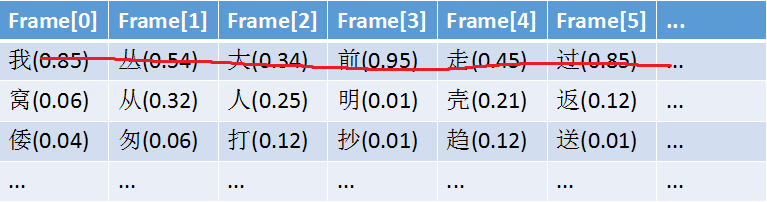
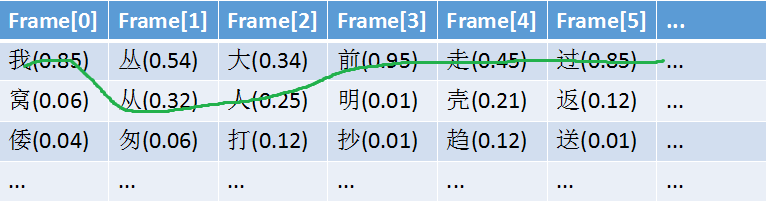
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
|
import numpy as np
import random
vocab = {
0: 'a',
1: 'b',
2: 'c',
3: 'd',
4: 'e',
5: 'BOS',
6: 'EOS'
}
reverse_vocab = dict([(v,k) for k,v in vocab.items()])
vocab_size = len(vocab.items())
def softmax(x):
"""Compute softmax values for each sets of scores in x."""
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum()
def reduce_mul(l):
out = 1.0
for x in l:
out *= x
return out
def check_all_done(seqs):
for seq in seqs:
if not seq[-1]:
return False
return True
def decode_step(encoder_context, input_seq):
words_prob = [random.random() for _ in range(vocab_size)]
words_prob[reverse_vocab['BOS']] = 0.0
words_prob = softmax(words_prob)
ouput_step = [(idx,prob) for idx,prob in enumerate(words_prob)]
ouput_step = sorted(ouput_step, key=lambda x: x[1], reverse=True)
return ouput_step
def beam_search_step(encoder_context, top_seqs, k):
all_seqs = []
for seq in top_seqs:
seq_score = reduce_mul([_score for _,_score in seq])
if seq[-1][0] == reverse_vocab['EOS']:
all_seqs.append((seq, seq_score, True))
continue
current_step = decode_step(encoder_context, seq)
for i,word in enumerate(current_step):
if i >= k:
break
word_index = word[0]
word_score = word[1]
score = seq_score * word_score
rs_seq = seq + [word]
done = (word_index == reverse_vocab['EOS'])
all_seqs.append((rs_seq, score, done))
all_seqs = sorted(all_seqs, key = lambda seq: seq[1], reverse=True)
topk_seqs = [seq for seq,_,_ in all_seqs[:k]]
all_done = check_all_done(topk_seqs)
return topk_seqs, all_done
def beam_search(encoder_context):
beam_size = 3
max_len = 10
top_seqs = [[(reverse_vocab['BOS'],1.0)]]
for _ in range(max_len):
top_seqs, all_done = beam_search_step(encoder_context, top_seqs, beam_size)
if all_done:
break
return top_seqs
if __name__ == '__main__':
encoder_context = None
top_seqs = beam_search(encoder_context)
for i,seq in enumerate(top_seqs):
print 'Path[%d]: ' % i
for word in seq[1:]:
word_index = word[0]
word_prob = word[1]
print '%s(%.4f)' % (vocab[word_index], word_prob),
if word_index == reverse_vocab['EOS']:
break
print '\n'
|